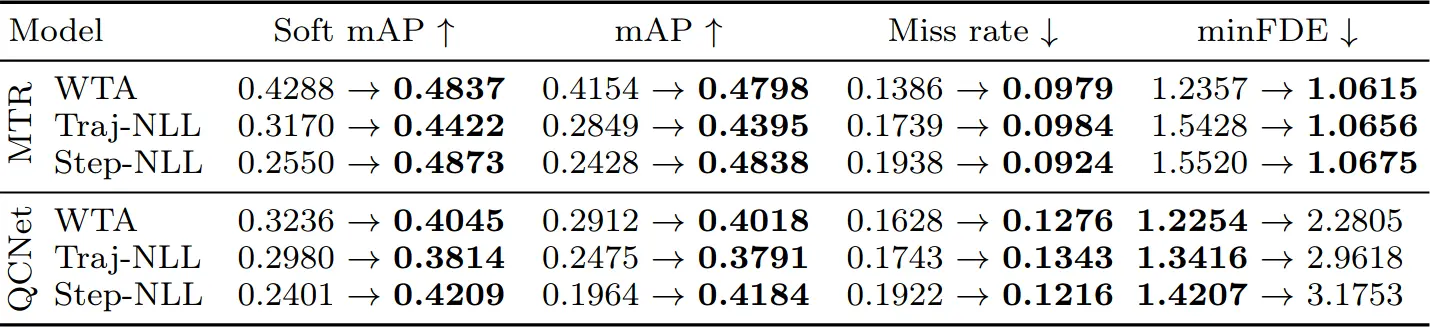
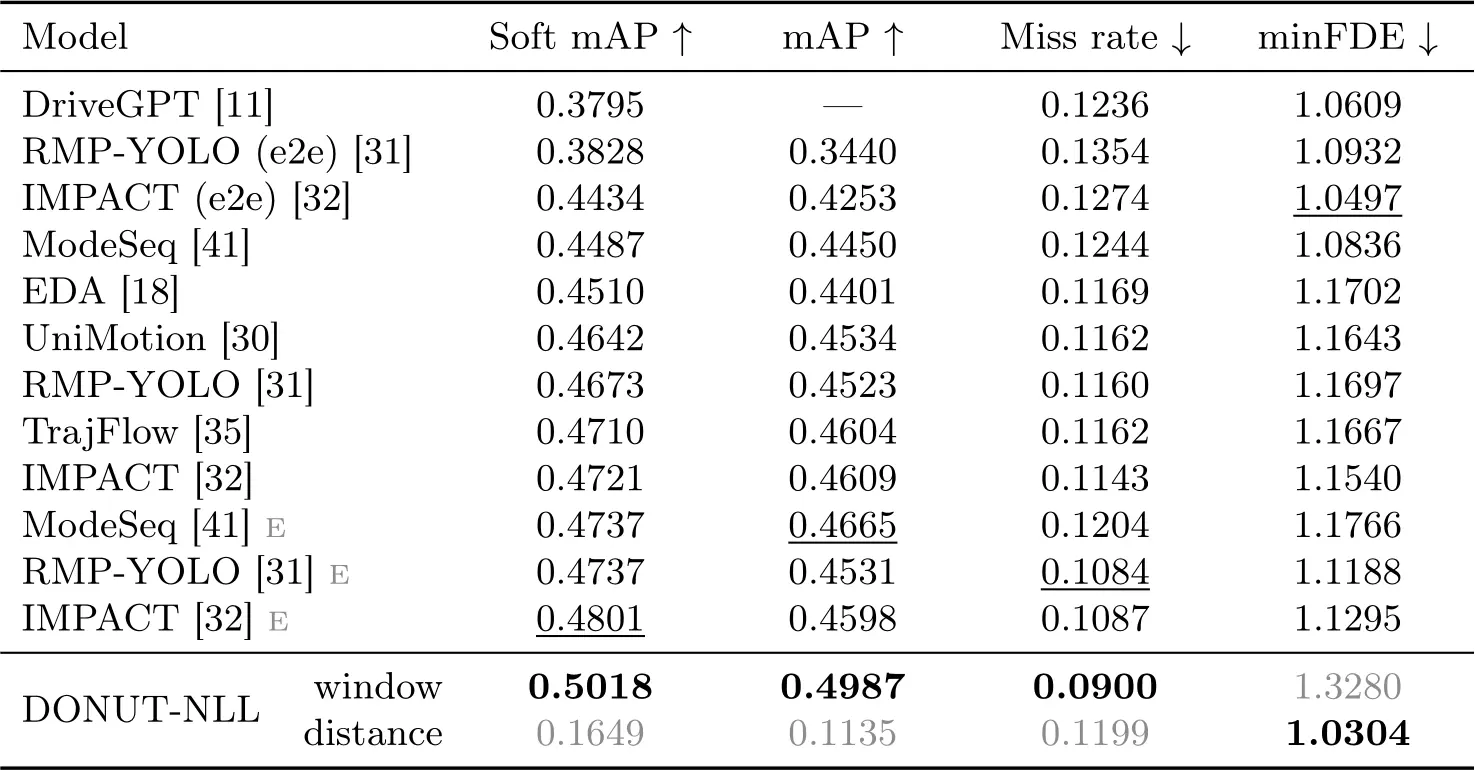
Trajectory Forecasting Metrics
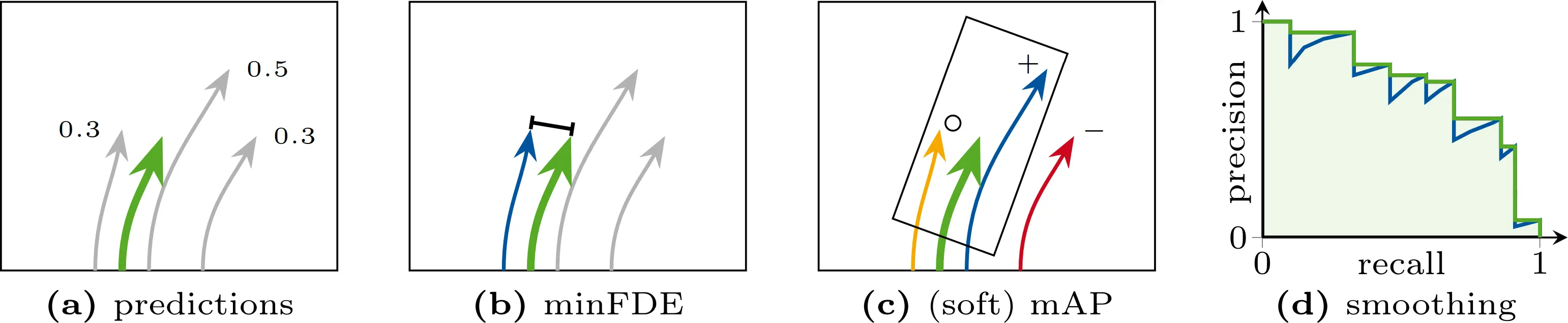
(a) A trajectory prediction model outputs predictions with assigned confidences.
(b) For the distance-based metric minFDE, the endpoint distance between ground truth and closest prediction is calculated.
(c) For the window-based metric (soft) mAP, an oriented window is placed around the ground-truth endpoint. The highest-confidence trajectory within the window (+) counts as a true positive, additional trajectories within the window (○) are either counted as false positives (mAP) or ignored (soft mAP). Predictions outside the window (−) count as false positives.
(d) To obtain the (soft) mAP, a precision-recall curve is created for each confidence score over the entire dataset and then smoothed; the area under the curve is the final metric.
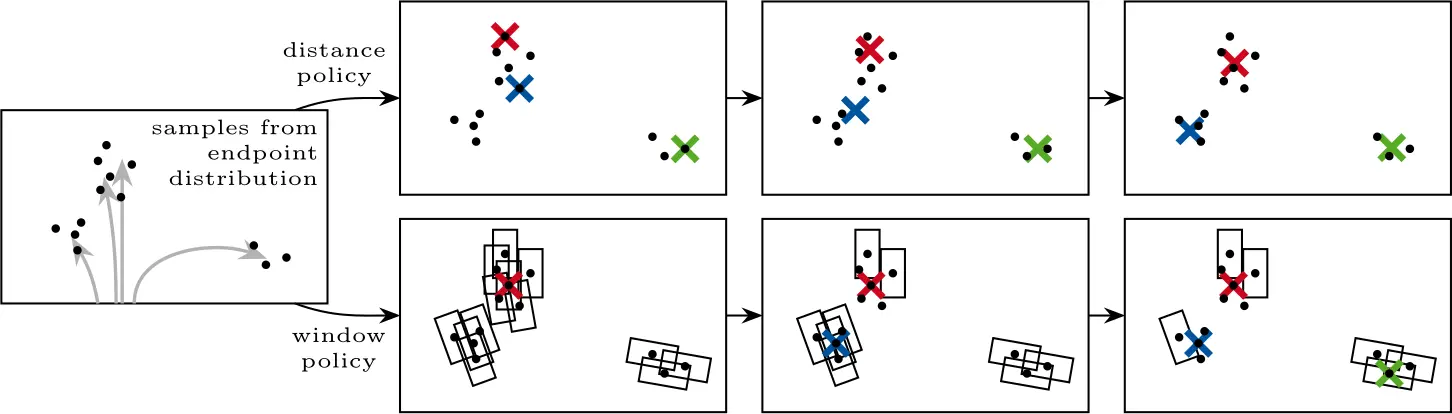
Crucially, these metrics reward conflicting goals: minFDE improves if many endpoints are close to the main mode, whereas endpoints within the same window in (soft) mAP get penalized or ignored.